Reading Order (NID)
Measures whether text is extracted in the correct sequence
Why Reading Order Matters for RAG
When a PDF has multiple columns, sidebars, or complex layouts, many parsers read text left-to-right across the entire page — mixing content from different sections. This creates incoherent chunks that confuse LLMs and produce wrong answers.
Example problem: A two-column academic paper where the parser jumps between columns mid-sentence, making the extracted text unreadable.
What NID Measures
NID (Normalized Indel Distance) compares the extracted text against human-verified ground truth. A score of 1.0 means perfect order; lower scores indicate text was scrambled or misplaced.
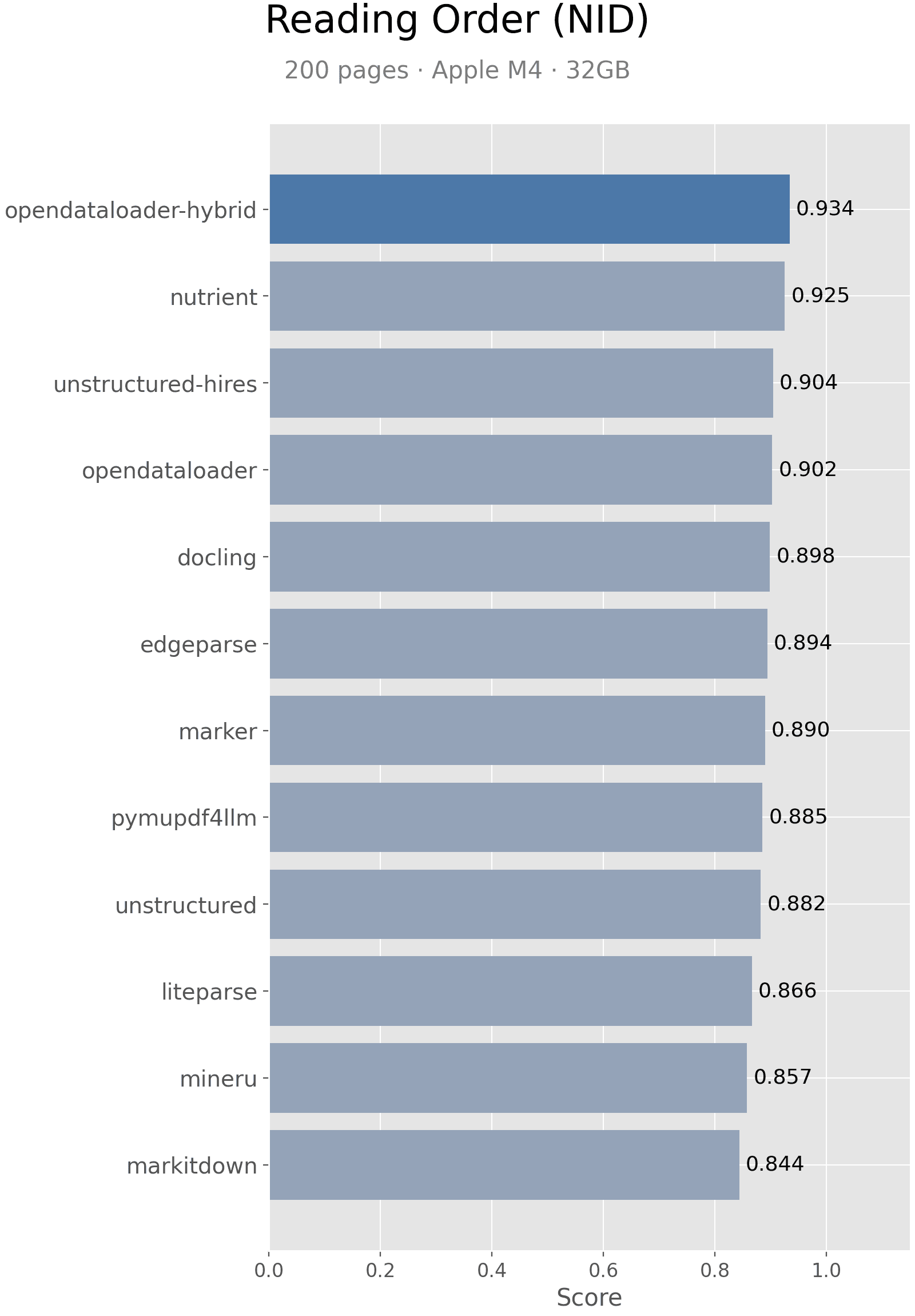
Results
| Engine | Score | Rank |
|---|---|---|
| OpenDataLoader [hybrid] | 0.934 | #1 |
| Nutrient | 0.925 | #2 |
| Unstructured [hi_res] | 0.904 | #3 |
| OpenDataLoader | 0.902 | #4 |
| Docling | 0.898 | #5 |
| Edgeparse | 0.894 | #6 |
| Marker | 0.890 | #7 |
| PyMuPDF4LLM | 0.885 | #8 |
| Unstructured | 0.882 | #9 |
| LiteParse | 0.866 | #10 |
| MinerU | 0.857 | #11 |
| MarkItDown | 0.844 | #12 |
- All engines score 0.86+ — basic reading order is a solved problem for simple documents
- Gaps appear in complex layouts — multi-column, mixed text/table, and nested sections reveal differences
When to Prioritize This Metric
| Use Case | Recommended Engine |
|---|---|
| Multi-column layouts | OpenDataLoader |
| Academic papers, reports | OpenDataLoader |
| Simple single-column documents | Any engine works |
Learn More
For detailed methodology, raw data, and reproduction scripts, see the opendataloader-bench repository.