Table Structure (TEDS)
Measures whether tables are accurately reconstructed
Why Table Extraction Matters for RAG
Tables contain structured data that LLMs need to answer questions like "What was Q3 revenue?" or "Compare Product A vs B." If rows and columns are scrambled or merged incorrectly, the LLM gets wrong data and gives wrong answers.
Example problem: A financial table where cell values shift to wrong columns, causing the LLM to report incorrect figures.
What TEDS Measures
TEDS (Tree Edit Distance Similarity) compares the structure of extracted tables against ground truth. A score of 1.0 means perfect reconstruction; lower scores indicate missing rows, merged cells, or scrambled content.
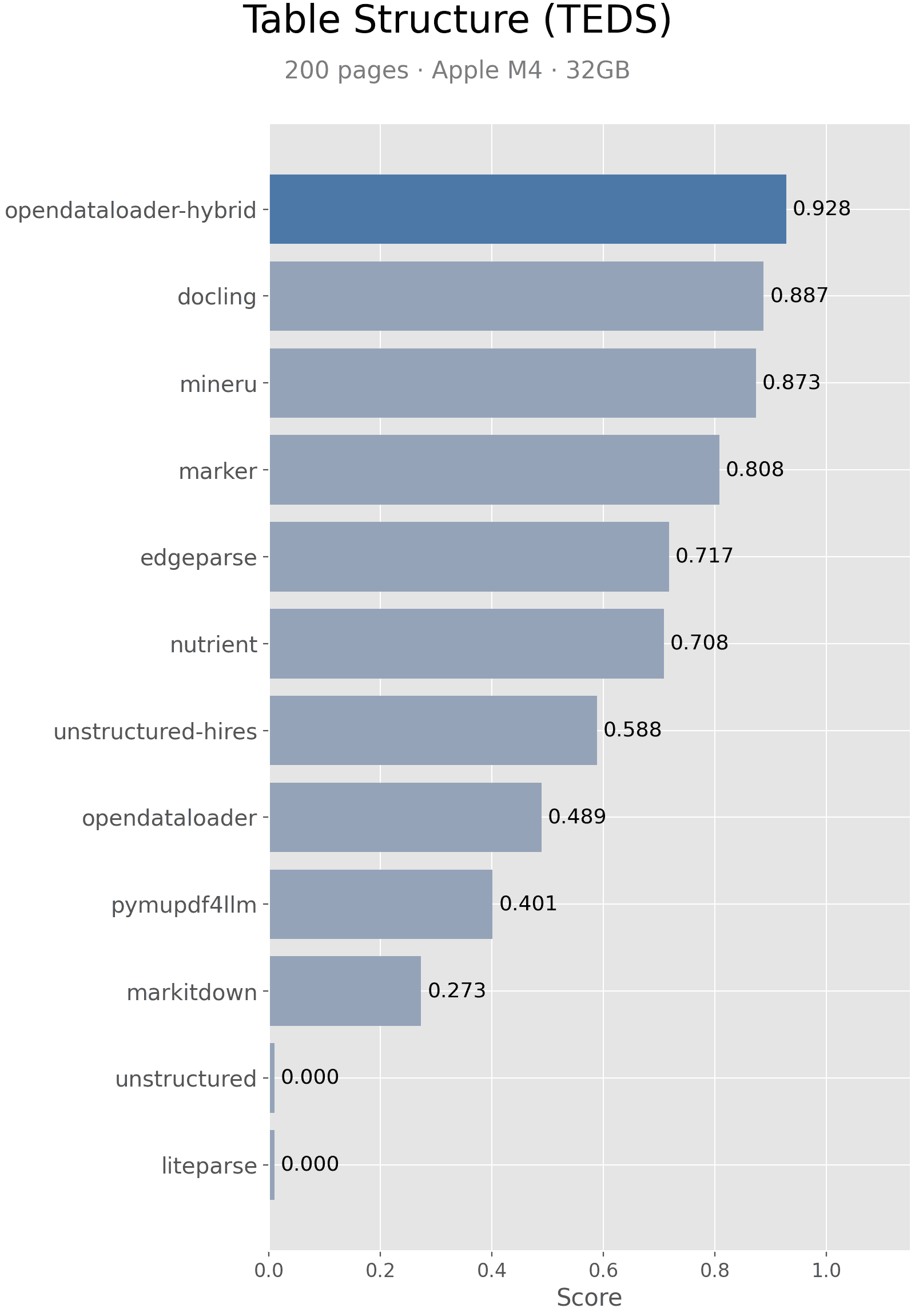
Results
| Engine | Score | Rank |
|---|---|---|
| OpenDataLoader [hybrid] | 0.928 | #1 |
| Docling | 0.887 | #2 |
| MinerU | 0.873 | #3 |
| Marker | 0.808 | #4 |
| Edgeparse | 0.717 | #5 |
| Nutrient | 0.708 | #6 |
| Unstructured [hi_res] | 0.588 | #7 |
| OpenDataLoader | 0.489 | #8 |
| PyMuPDF4LLM | 0.401 | #9 |
| MarkItDown | 0.273 | #10 |
| Unstructured | 0.000 | #11 |
| LiteParse | 0.000 | #11 |
- Table extraction remains the hardest problem — scores range widely from 0.00 to 0.93
- Borderless tables, nested headers, and merged cells cause errors across all engines
When to Prioritize This Metric
| Use Case | Recommended Engine |
|---|---|
| Financial documents with tables | Docling |
| Technical specs, comparison tables | Docling |
| Simple bordered tables | OpenDataLoader |
| No tables in documents | Any engine works |
Current Limitations
If your documents are table-heavy, test with your actual files before choosing an engine. Consider post-processing or manual review for critical data.
Learn More
For detailed methodology, raw data, and reproduction scripts, see the opendataloader-bench repository.