Extraction Speed
Measures processing speed per document
Why Speed Matters
Processing time directly impacts cost and user experience. A 10x slower parser means 10x more compute cost at scale — or unacceptable wait times for interactive applications.
What We Measure
Average seconds per page across the benchmark corpus, covering the full pipeline: PDF parsing, layout analysis, and Markdown generation.
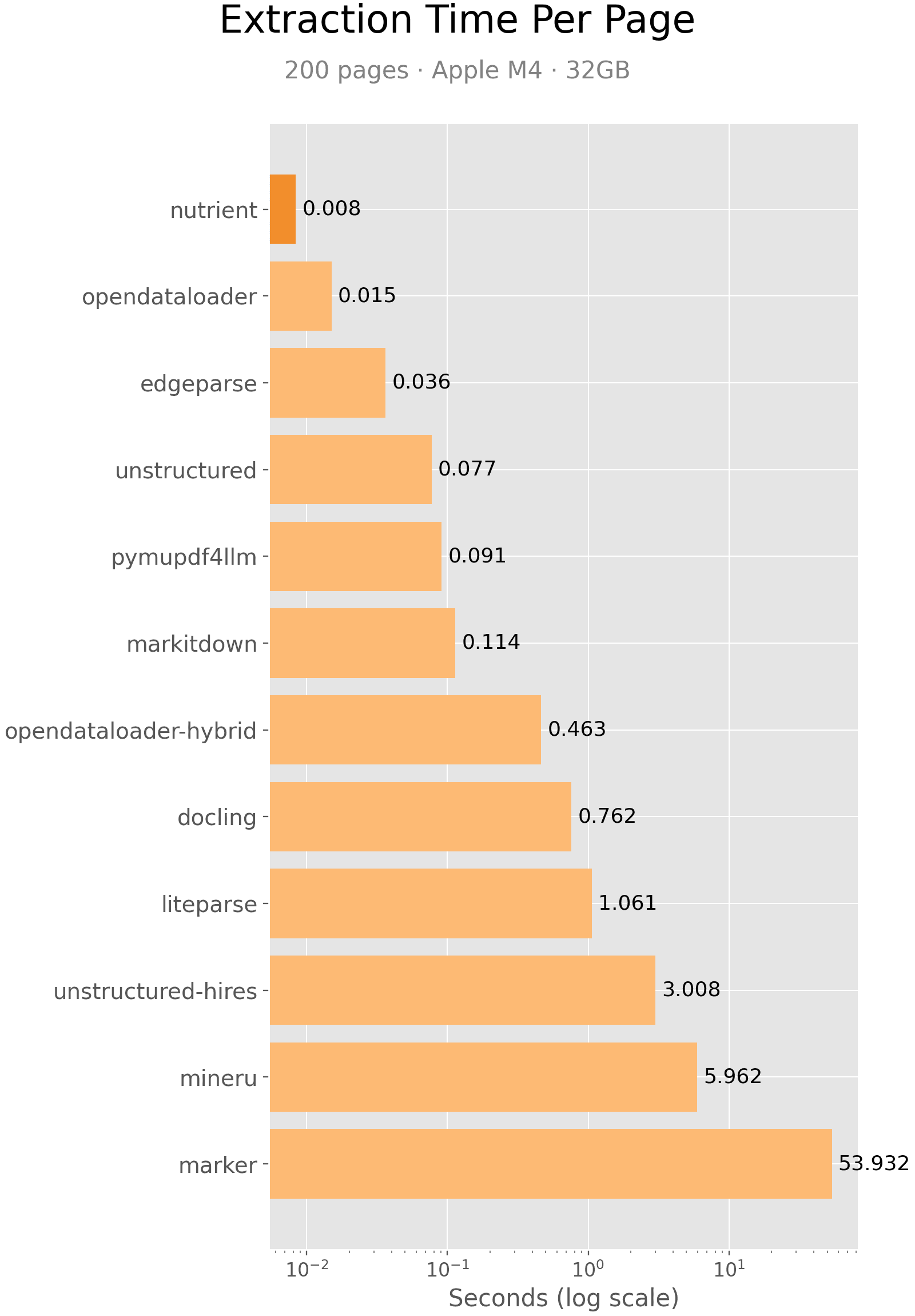
Results
| Engine | Speed (s/page) | Rank |
|---|---|---|
| Nutrient | 0.008 | #1 |
| OpenDataLoader | 0.015 | #2 |
| Edgeparse | 0.036 | #3 |
| Unstructured | 0.077 | #4 |
| PyMuPDF4LLM | 0.091 | #5 |
| MarkItDown | 0.114 | #6 |
| OpenDataLoader [hybrid] | 0.463 | #7 |
| Docling | 0.762 | #8 |
| LiteParse | 1.061 | #9 |
| Unstructured [hi_res] | 3.008 | #10 |
| MinerU | 5.962 | #11 |
| Marker | 53.932 | #12 |
When to Prioritize Speed
| Use Case | Recommended Engine |
|---|---|
| Batch processing (1000s of docs) | OpenDataLoader |
| Real-time / interactive apps | OpenDataLoader or MarkItDown |
| Cost-sensitive deployments | OpenDataLoader |
| Accuracy-critical, time flexible | Docling |
Notes
- Measurements are single-threaded on CPU
- Multi-threading and GPU acceleration can change rankings
- All engines run locally — no network latency
Learn More
For detailed methodology, raw data, and reproduction scripts, see the opendataloader-bench repository.